

TL;DR
robots.txt file sometimes gets overlooked, while it can have a tremendous effect on crawl budget, eliminating thin content and on the other side of the coin – with a bad implementation it can lead to some major issues – such as blocking CSS and JS files accidently.
In the following post I’ll review the most important rules and more advanced hacks that you should be aware of when analyzing or writing a new robots.txt file.
Huge thanks to John Müller who found the time to read the post and sent me a few comments and correction. It’s always best to get your confirmation from the source. 🙂
1. You can host a sitemap.xml on a different domain
I have to admit that for years I didn’t understand the logic behind stating the location of the sitemap.xml in the robots.txt file, after all , you can submit the sitemap.xml via Google Search Console.
However, what about a case where we have company.example.com and we want its sitemap.xml to be hosted on blog.example.com, in other words two different hosts?
So the robots.txt on company.example.com will include the following line:
Sitemap: http://blog.example.com/sitemap.xml
All you need to do is to specify on your robots.txt where the location of the sitemap.xml
It’s important to bear in mind that you can specify more than one sitemap.xml for every robots.txt, but it WON’T work if the two hosts deployed different protocol (http vs. https)
To submit Sitemaps for multiple hosts from a single host, you need to “prove” ownership of the host(s) for which URLs are being submitted in a Sitemap.
2. You can monitor robots.txt changes with Wayback Machine
That’s actually a great tool to check the history of the robots,txt file and what changes have been made over time.
All you have to do is enter the URL to the WayBack Machine. I just been noticed about a client which his robots.txt was blocked and we needed to check when this change took place. Wayback Machine to the rescue!

3. The length of the entry counts
According to Google documentation the longest rule will trump the shorter rule. In other words, the more specific rule will rule them all.
Why it’s so important?
Let’s say we would like to allow CSS and JS files (according to Google recommendation) and we have the following lines in our robots.txt file:
User-agent:
Disallow: /wp-content/
Allow: /.js
Allow: /.css
If the /wp-content/ folder contains all the CSS and JS files (as with 99.9% of WordPress sites) then the two lines that allegedly allow these type files won’t count.
Why?
Because the line the blocks the folder (Disallow: /wp-content/) is longer than the other two above
How to fix it?
Just add this line:
allow: /wp-content/*.js
Now the line is longer . Sounds weird, right? Try it, it works.
4. Robots.txt is case sensitive
From all, this is probably the most obvious for most of SEO’s however, it’s highly important to emphasize and remember that
For example:
User-agent: *
Disallow: /Content/
If the URL is : example.com/content/ it WON’T be blocked since it’s not identical.
John Mueller Tip about case sensitive robots.txt

For extra points, Bing’s robots.txt handling is not case-sensitive
5. You can Noindex pages via the robots.txt file
@maxxeight @google @DeepCrawl I'd really avoid using the noindex there.
— John ☆.o(≧▽≦)o.☆ (@JohnMu) September 1, 2015
Although John Muller asked in the past to avoid this practice (back in September 2015) from my experiences I found this method works like magic. While it can serve as a great alternative to avoid development bottle necks and deploy the noindex tag as easily as it gets, I find that SEO’s are less aware of it and rarely use it, at least less than you would expect.
Also, since his statement, I remember John had stated it’s OK to use this directive, unfortunately I haven’t found the relevant post or Tweet to confirm it (if you have the reference – please send it to me and I’ll give you a credit).
All you have to do is add the following line:
Noindex: /example-page/
Unlike the other robots.txt directives, this is URL specific only, which means you can’t noindex a full directory this way.
6. Disallow and noindex is a bad combination
Let’s say you added the following line:
User-agent: *
Disallow: /page.html
And simultaneously you added Meta robots tag with noindex.
What will happen?
Well, simply the bots will see neither the page’s code or meta tags as robots.txt disallow crawling it in the first place. So ask yourself, should I implement meta robots or robots.txt for a specific page/directory? Both won’t be a good answer in most cases.
7. What about mobile first index? Does it deploy a different bot?
The short answer is no. If you want to block certain pages for mobile only – use Googlebot user agent.
As Google emphasized it mobile first index is not separate from the main index, it just means Google will use the mobile version for indexing and ranking.
So, if you want to block (or allow) some URL’s from both the desktop and mobile version, stating Googlebot will be sufficient for both.
8. UTF-8 Bom – the invisible character
Without getting too technical, byte order mark (bom) is a unicode character that indicates the beginning of the next stream.
Why is that bad? Well, in case the robots.txt file is encoded with bom, Google (and the other search engines) will ignore the first line, which often means – the user agent. And in this case – it will probably see all the other lines as errors and ignore them as well.
So how will you recognize you have an issue?
Check your robots.txt in Google search console:
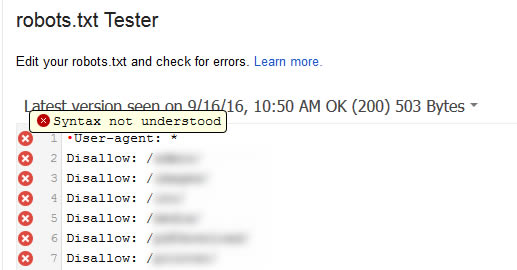
In this case (syntax not understood), it probably means that your robots.txt file is saved with utf-8 bom format.
What should you do in this case?
Easy, copy paste the lines to Notpad++.Then, save the file as utf-8 without bom:

And upload the new robots.txt to the root domain. Check your robots.txt in the Search Console a few days later (depends on your site) and just make sure there are no notifications or other red signs.
John Mueller Tip about UTF-8 Bom
A simple way to get around that is to always have a comment line on top of your robots.txt file. Also, one BOM is fine, that’s a part of unicode text files. Two BOMs are where it causes problems (and since you usually don’t “see” them, that can happen)
TL;DR
So what’s your experience with robots.txt? Do you have any common mistakes that you would like to share with us?
Hi Roy,
Google seems to have updated the crawl behaviour regarding the (one) BOM at the beginning of robots.txt: “An optional Unicode BOM (byte order mark) at the beginning of the robots.txt file is ignored.” (https://developers.google.com/search/reference/robots_txt?hl=en). Search Console is still showing errors, but Google seems to follow all rules in the robots.txt file, although user-agent is defined in the first row with the BOM at first position.
Cheers,
Hans
Hey Hans, thanks for the clarification!
I will try to check with John Muller as well